
Cursor + MCP aims to disrupt not just the frontend
At the end of 2024, I still believed AI replacing programmers was an unattainable prospect. However, through personal learning and intensive team discussions/practices in the AI Code field, my views have undergone a 180-degree reversal — AI’s takeover of junior programmers’ coding tasks is now imminent. This article shares the AI capabilities that changed my perspective and my understanding of future AI Code.
“Long-term — note that my ‘long-term’ likely means 18-24 months rather than 5-6 years — we might see ‘replacement’ phenomena emerge at junior coding levels, possibly even sooner,” Dario stated bluntly in the interview. This timeline is significantly shorter than most industry experts anticipated, particularly considering his definition of “long-term” being merely 1.5-2 years.
— February 2025, Dario Amodei, CEO of Anthropic
Agent VS Workflow
Manus’ explosive popularity has suddenly made many realize that numerous products now claim to be AI Agents, much like how countless foods market themselves as “all-natural” — the term “Agent” has been overused. Just as some question Manus’ authenticity, many so-called Agents are merely pre-orchestrated Workflows. Since Workflows can call upon large models internally, they appear equally “AI,” making it hard to distinguish Workflows from true Agents.
The key distinction lies in autonomous decision-making:
- Workflow resembles a fixed production line where every step is pre-designed.
- Agent acts like an assistant with independent thinking, following a perceive-decide-act loop to autonomously determine methods and duration.
Ultimately, true Agents exhibit two critical characteristics:
- Self-directed decisions: No need for human instructions at every step.
- Persistent execution until completion: Iterations adapt dynamically rather than following preset limits.
Consider these kitchen scenarios:
- Workflow: Follows a recipe rigidly — chop vegetables → add oil → stir-fry. Each step is predefined and executed step-by-step. If oil runs out, cooking halts.
- Agent: Given the goal “make a delicious dinner,” it inventories the fridge, decides the dish, cooking method, and steps. If oil is missing, it autonomously resolves the issue (e.g., purchasing more).
The most suitable task characteristics for agents
When choosing scenarios for Agent applications, Barry from Anthropic proposed a practical criterion:
“The most suitable tasks for Agents are those that are both complex and valuable, yet carry low risks if failed or require minimal monitoring costs. This represents the ideal intersection for Agent deployment.”
In essence, the most appropriate tasks for Agents should exhibit:
- Sufficient complexity: Simple tasks might be “using a sledgehammer to crack a nut” with Agents.
- Tangible value: Worth automating with resource investments.
- High fault tolerance: Occasional errors won’t cause severe consequences, especially under human supervision.
For example, you might delegate email filtering or document organization to an Agent, as misclassification errors would have minor repercussions. However, you’d likely avoid letting Agents handle large bank transfers directly due to high error costs.
Search exemplifies this perfectly: a highly valuable task where iterative, in-depth retrieval is challenging. Agents can conduct multi-round searches, dynamically adjusting strategies to pinpoint user needs rather than relying on keyword matching. This explains the success of Agent-powered search systems like Perplexity and Alibaba.com’s Accio.
Another domain perfectly aligning with these characteristics is coding:
- Cursor’s Yolo mode autonomously evaluates terminal command execution states, automatically debugging and rerunning code after compilation errors.
- Windsurf’s AI Flows decompose complex tasks into multi-step workflows, monitoring file changes in real-time to adjust subsequent operations.
Even ByteDance’s recently launched Trae mirrors this trend, shifting from tab-based prompts in MarsCode to Agent-driven interactions. Modern IDEs now transcend traditional code completion, evolving into environment-aware collaborators where context perception + autonomous decision-making are becoming next-generation standard features.
Challenges of AI for Programmers
Coding occupies less than 50% of programmers’ time, and current AI programming tools still can’t fully replace humans. Let’s clarify how programmers actually work:
- Participate in requirement reviews and design reviews to clarify objectives
- Design technical solutions using professional knowledge
- Build code frameworks with enterprise/community solutions
- Implement and refine code:
a. Debug through error messages
b. Research online resources
c. Consult domain experts - Conduct unit testing
- Integration testing, smoke testing, and project acceptance
After understanding Agent capabilities, programmers’ irreplaceability seems concentrated in requirement comprehension and technical design that depend on internal enterprise knowledge — areas where AI struggles. Other tasks could be delegated to Agents under human supervision.
The previous sense of security (“AI can’t replace me”) stemmed from two limitations:
- Single-file Tab suggestions couldn’t integrate project best practices
- AI lacked understanding of internal enterprise norms: code standards, base components, middleware, frameworks
However, recent three-month advancements in AI (Agent patterns, context awareness, etc.) reveal this assumption to be overly optimistic.
Codebase Indexing: Understanding Full Project Context
Cursor fundamentally addressed the first challenge through Codebase Indexing, effectively eroding half of programmers’ “moat” defenses.

When opening a project in Cursor, it automatically scans and indexes the codebase. This process analyzes code elements like functions, classes, and variables while establishing their interrelationships. Through this mechanism, AI can rapidly locate relevant code snippets and understand their context and purpose.
- Context-aware code association: Identifies overload patterns like
getUserInfo()across different modules - Cross-file semantic tracing: Automatically locates implementation classes via interface definitions
- Incremental updates: Newly added files complete index synchronization within 30 seconds of saving
With these capabilities, when developers request code generation, AI leverages indexed information to produce code aligned with the project’s existing patterns and styles, significantly enhancing contextual relevance.
RAG + Function Call Enables Models to Better Understand Enterprises
Traditional approaches to addressing models’ lack of enterprise/internal or specialized domain knowledge primarily rely on model fine-tuning. While fine-tuning can inject domain-specific knowledge, it persistently suffers from hallucinations and reduced generalization capability, alongside the “knowledge ossification” dilemma — adjusted parameters cannot dynamically adapt to evolving business rules. Moreover, high-frequency full fine-tuning incurs substantial computational and budgetary costs.
For domain knowledge expansion alone, RAG (Retrieval-Augmented Generation) emerges as a viable alternative, addressing real-time knowledge updates and cost efficiency. However, it confines AI-generated code to predefined workflow orchestration modes, requiring developers to manually activate RAG with specific trigger phrases and assemble prompts (e.g., “call component library, rewrite code using Button component”). Although industry practices like Microsoft’s GraphRAG (enabling multi-hop reasoning via knowledge graphs) demonstrate progress toward “unconscious intelligence”, their adoption remains limited due to technical complexity and implementation costs.
Function Calling proves revolutionary by translating natural language instructions into structured API requests to execute operations or fetch real-time data. Per OpenAI’s latest guidelines, its “data acquisition” mode essentially implements RAG — proactively triggering knowledge base retrieval via Function Calls before generating responses. This mechanism enables LLMs to achieve cognitive leap from passive response to active knowledge-seeking paradigms.

from openai import OpenAI
client = OpenAI()
tools = [{
"type": "function",
"name": "get_weather",
"description": "Get current temperature for a given location.",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "City and country e.g. Bogotá, Colombia"
}
},
"required": [
"location"
],
"additionalProperties": False
}
}]
response = client.responses.create(
model="gpt-4o",
input=[{
"role": "user",
"content": "What is the weather like in Paris today?"
}],
tools=tools
)
print(response.output)
Function Call requires injecting the full API response data into prompts with each invocation, causing linear expansion of context length. Its ecosystem remains highly fragmented as different model vendors define their own function-calling formats (e.g., OpenAI’s JSON structure), forcing cross-platform developers to implement redundant adaptations. Each new API integration demands approximately 20+ hours of development effort due to the manual three-phase workflow: function definition → model adaptation → result parsing.
However, this complexity is beginning to unravel under the impact of MCP (Model Context Protocol), which introduces standardized context management and eliminates redundant data injection through modular architecture.
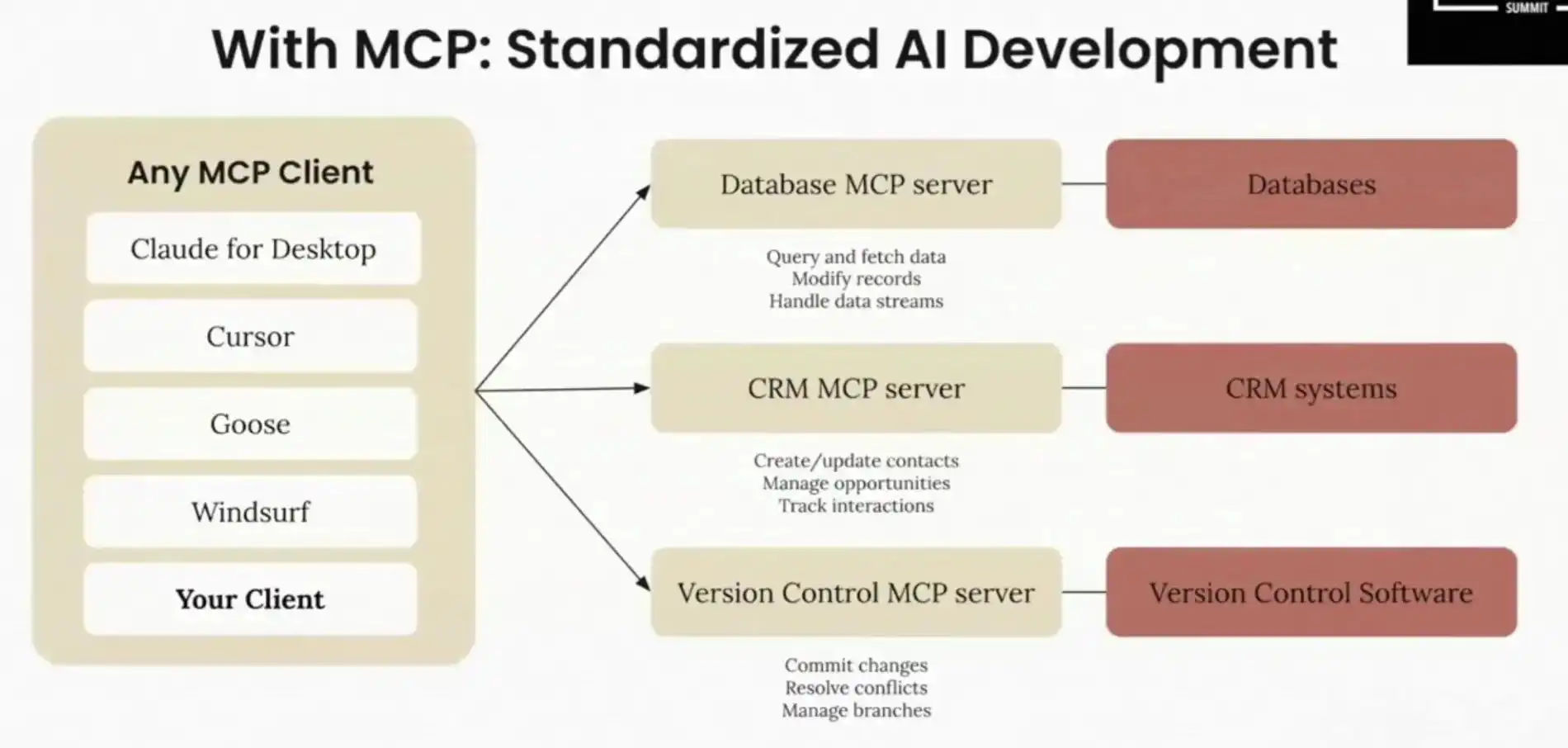
MCP: The USB-C for Large Models and Enterprise Knowledge
What is MCP
The Model Context Protocol (MCP) lets you build servers that expose data and functionality to LLM applications in a secure, standardized way. Think of it like a web API, but specifically designed for LLM interactions.

In simple terms, MCP (Model Context Protocol) is an open protocol proposed by Anthropic to standardize how applications provide context to large language models (LLMs), acting as a “USB-C” interface between models and various applications.
MCP adopts a client-server (C/S) architecture with standardized JSON-RPC-based messaging:
- MCP Client: Embedded in AI applications (e.g., Cursor), it “converses” with servers, intelligently initiating MCP service calls based on natural language inputs to retrieve data, resources, or execute commands.
- MCP Server: A service provided by developers to expose internal data, resources, and functionalities to models.
Key Roles of Cursor in Supporting MCP
The data flow between Cursor, MCP Server, and models forms a standardized collaboration framework, enabling efficient interactions via the MCP protocol:
- Cursor as MCP Client: Initiates requests, displays results, and serves as the user-system interaction interface.
- MCP Server: Provides standardized interfaces for processing client requests, connecting to local/remote resources (e.g., GitHub API, file systems), and returning structured data.
- Model: Receives requests/context from Cursor, generates decisions (e.g., tool invocation needs), and produces natural language responses.
MCP Data Flow
Phase I: Initialization & Connection
- Cursor initializes MCP Client upon startup, establishing connections with project/IDE-configured MCP Servers.
- Capability negotiation occurs to identify available resources/tools from Servers.
Phase II: Request Processing
- Request Routing: User inputs natural language commands → Cursor forwards requests to MCP Server → Obtains tool descriptions → Combines tool list with user instructions → Sends to model.
- Model Decision: Model parses requests, determines required tools, generates structured parameters → Cursor executes tool calls via MCP Server.
Phase III: Data Integration
- Execution: MCP Server processes requests → Returns results via JSON-RPC 2.0 protocol to Cursor.
- Final Response: Cursor sends results to model → Model integrates context → Generates natural language response → Cursor displays final output.
Since model decisions determine tool invocation, an additional model invocation is required when MCP Server calls are needed.
Core Advantages of MCP
- Protocol Standardization Drives Ecosystem Unification: MCP simplifies AI-tool integration via a unified protocol, eliminating the need for per-tool interface development and enabling one-time integration for multi-tool reuse.
- Development Efficiency: MCP’s official SDK and debugging tools streamline MCP Server implementation. Compared to model-specific Function Call adaptations, building a universal MCP Server is exceptionally straightforward:
from mcp.server.fastmcp import FastMCP
# Create an MCP server
mcp = FastMCP("Demo")
# Add an addition tool
@mcp.tool()
def add(a: int, b: int) -> int:
"""Add two numbers"""
return a + b
# Add a dynamic greeting resource
@mcp.resource("greeting://{name}")
def get_greeting(name: str) -> str:
"""Get a personalized greeting"""
return f"Hello, {name}!"
- Eliminates Context Explosion: MCP employs modular context management, abstracting external data sources into independent modules. Models activate specific modules only when needed. Combined with incremental indexing that syncs only changed data, token consumption is reduced by 60-80% compared to Function Call’s full-context injection.
- Dynamic Discovery & Flexibility: MCP enables dynamic discovery of available tools, allowing AI to automatically recognize and invoke newly integrated data sources/functionalities without pre-configuration.
MCP redefines AI-system collaboration through protocol-layer innovation, addressing Function Call’s core limitations—ecosystem fragmentation, context redundancy, and coarse-grained permissions—with standardized, dynamic, and secure features. Backed by Anthropic’s ecosystem momentum (particularly Claude’s adoption), MCP is poised to become core infrastructure for next-gen intelligent systems.Here’s the English translation without expansion:
Function Calling vs MCP
At first glance, both address model-tool interaction, but their data flows differ fundamentally:
- Function Calling: User input → Model detects intent → Generates tool parameters → Executes external function → Returns & integrates results
- MCP: User input → Client requests available tools from MCP Server → Model generates natural language instructions → Client parses & invokes tools → Returns results → Model enhances response with results
Key Differences
- Dependency: Function Calling requires model-level support (e.g., GPT-4’s structured output), while MCP acts as a model-agnostic “plugin” — any model can leverage it through Client-server coordination.
- Design Philosophy:
- Function Calling extends model capabilities (“vertical optimization”)
- MCP establishes universal tool interaction infrastructure (“horizontal generalization”)
Function Calling (“magic” model features) and MCP (“no magic, just chat”) represent complementary approaches — specialized enhancement vs generalized interoperability — likely to coexist in future AI ecosystems.
The Paradigm of AI Code in Six Months
Future AI code-generation systems will form a closed-loop architecture of “Standard-Driven → Knowledge Accumulation → Protocol Integration → Intelligent Execution,” ensuring high-quality, maintainable, and intelligent code generation.
- Standard-Driven Architecture: A series of technical specifications and best practices ensure architectural rationality and generate enterprise-grade, highly available code.
- Business Knowledge Base: Serves as the core cognitive module for AI code generation, managing multi-modal knowledge with dynamic updates and intelligent retrieval.
- MCP Server: Acts as the system’s perceptual hub, interacting with various intelligent agents to collect and process development data for operational efficiency.
- IDE Integration: Combines intelligent coding workflows and multi-agent collaboration mechanisms to enhance efficiency through human-AI interfaces.
In this paradigm, frontend development evolves from D2C-generated UI code to full-stack solutions encompassing UI + data binding + interaction logic. For example, converting Figma designs to HTML is now simplified (e.g., https://glama.ai/mcp/servers/kcftotr525).
Final Remarks
Dario Amodei believes that as models grow increasingly powerful and capable, they will “break out of their current confines” in the real world. Some models with more research-oriented applications, which we’re also developing internally, will emerge soon. The next phase involves Agent systems capable of autonomously executing tasks, representing a whole new tier of capability. By then, I believe people will develop a deeper understanding of AI’s risks and benefits over the next two years than ever before. My only concern is that this awakening might arrive abruptly.
⚠️ While AI Code currently impacts frontend developers most severely, backend developers may face even greater disruptions within months.

Comments 0
There are no comments yet.